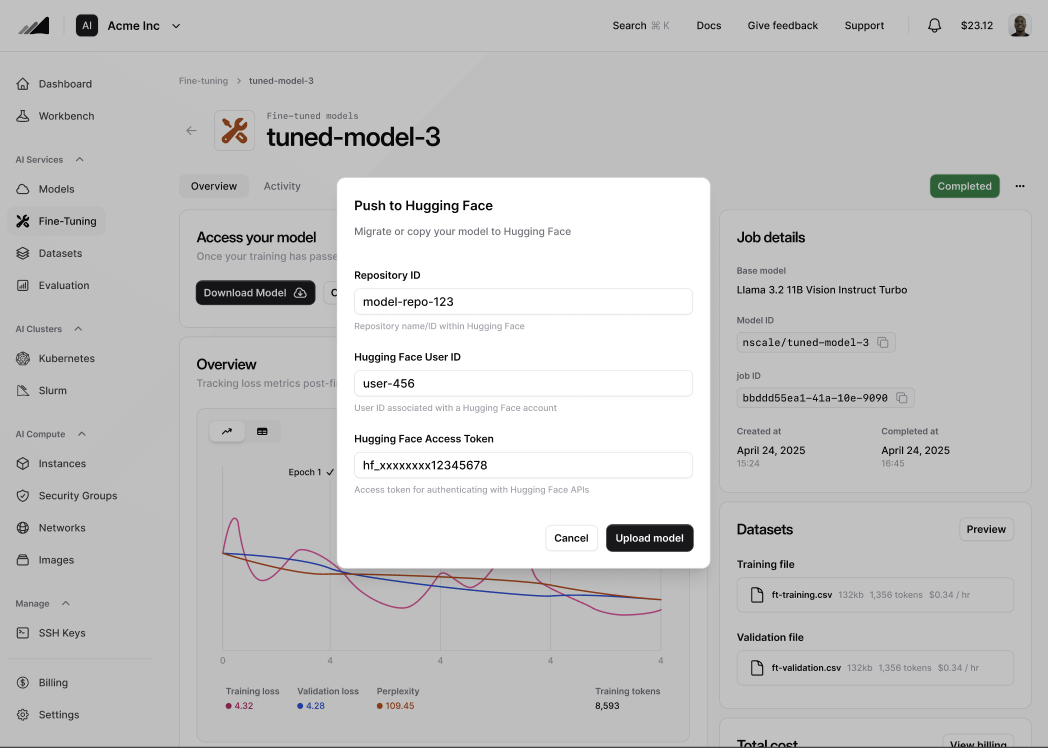
 **Push to Hugging Face**
Opens a dialog for your Hugging Face repository ID, user ID, and access token. Submit the form to start an export job that uploads the weights directly to your Hugging Face repository. The export surfaces as a running export on the same card until the upload finishes.
**Push to Hugging Face**
Opens a dialog for your Hugging Face repository ID, user ID, and access token. Submit the form to start an export job that uploads the weights directly to your Hugging Face repository. The export surfaces as a running export on the same card until the upload finishes.
 #### Via the API
Use these endpoints when you want to script exports without leaving your terminal.
**Push to Hugging Face**
The request body matches the fields collected by the Console dialog.
```bash theme={null}
curl -X POST "https://fine-tuning.api.nscale.com/api/v1/organizations/$ORGANIZATION_ID/jobs/$JOB_ID/exports/hugging-face" \
-H "Authorization: Bearer $NSCALE_API_TOKEN" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d '{
"huggingface_user_id": "your-hf-username",
"huggingface_access_token": "hf_xxx",
"huggingface_repository_id": "your-hf-username/your-model-repo"
}'
```
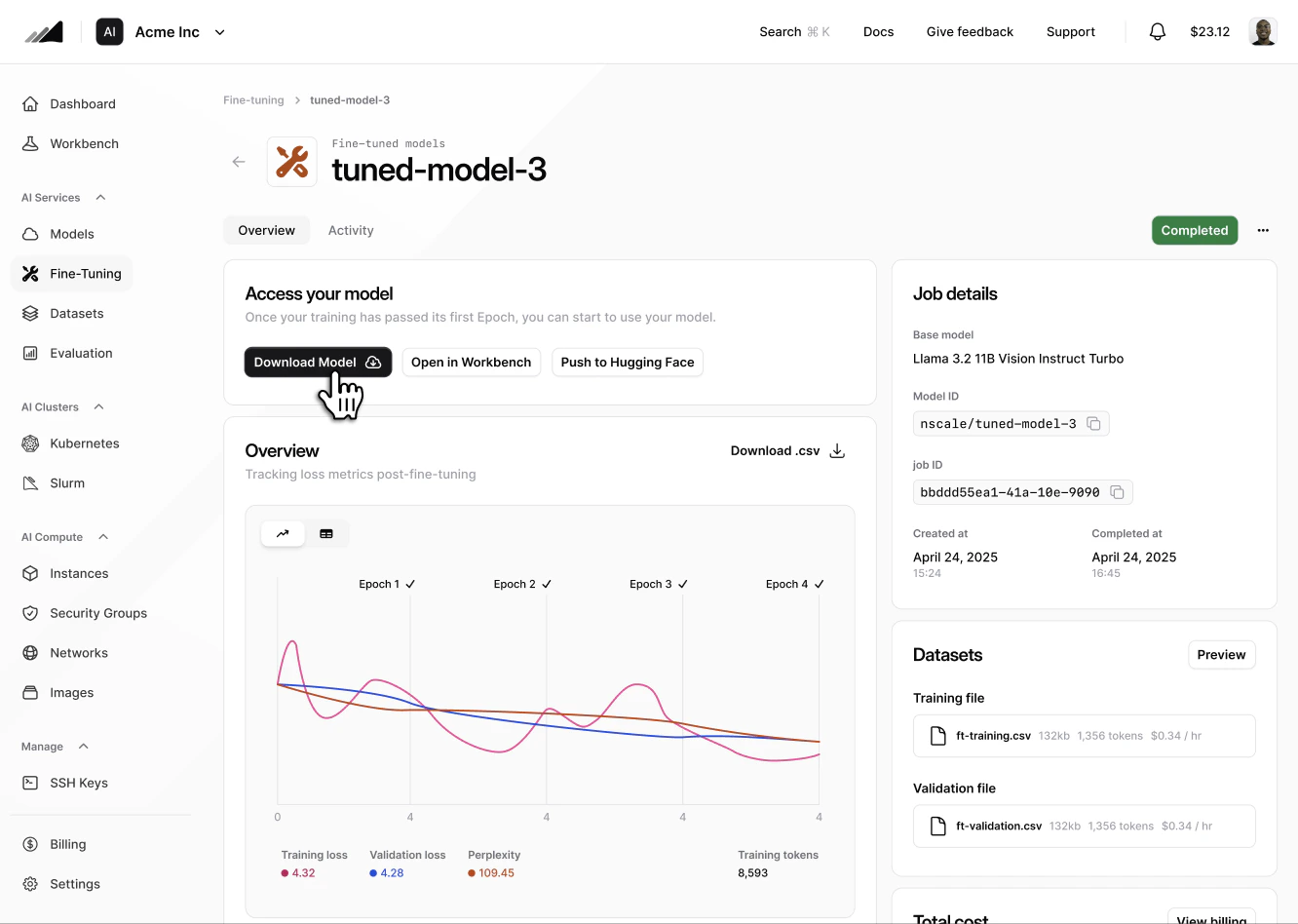
**Download the model archive**
This endpoint returns a redirect to a signed URL that streams the `.tar.gz` archive containing the model weights and configuration.
```bash theme={null}
curl -L -X GET "https://fine-tuning.api.nscale.com/api/v1/organizations/$ORGANIZATION_ID/jobs/$JOB_ID/download" \
-H "Authorization: Bearer $NSCALE_API_TOKEN" \
-o fine_tuned_model.tar.gz
```
#### With the Python client
The [`nscaledev/demo-nscale`](https://github.com/nscaledev/demo-nscale) repository ships a thin Python client around the fine-tuning APIs. The download helpers in [`nscale/finetuning.py`](https://github.com/nscaledev/demo-nscale/blob/main/nscale/finetuning.py) and [`nscale/files.py`](https://github.com/nscaledev/demo-nscale/blob/main/nscale/files.py) wrap the endpoints above so you can pull both the model archive and the original dataset files in one script.
```python theme={null}
from nscale import FineTuningClient
with FineTuningClient(api_token=token, organization_id=org_id) as client:
# 1) Download the fine-tuned model archive (.tar.gz)
client.jobs.download_model(
job_id="your-job-id",
output_path="exports/fine_tuned_model.tar.gz",
)
# 2) Download the dataset source files used to train the model
dataset = client.datasets.get("your-dataset-id")
client.files.download_file(
file_id=dataset["training_file_id"],
output_path="exports/train.csv",
)
if dataset.get("validation_file_id"):
client.files.download_file(
file_id=dataset["validation_file_id"],
output_path="exports/validation.csv",
)
```
Under the hood, `jobs.download_model()` calls the prepare-download endpoint to fetch a signed `download_url` and streams the response to disk. `files.download_file()` follows the same pattern for the original training and validation CSVs, so you keep a full record of the inputs alongside the trained weights.
## **Fine-tuning Job Cost Estimator**
The cost of a fine-tuning job is calculated based on the following factors:
* The number of token in your training and validation files.
* The number of traning and evaluation epochs.
* The base model you are using.
#### Via the API
Use these endpoints when you want to script exports without leaving your terminal.
**Push to Hugging Face**
The request body matches the fields collected by the Console dialog.
```bash theme={null}
curl -X POST "https://fine-tuning.api.nscale.com/api/v1/organizations/$ORGANIZATION_ID/jobs/$JOB_ID/exports/hugging-face" \
-H "Authorization: Bearer $NSCALE_API_TOKEN" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d '{
"huggingface_user_id": "your-hf-username",
"huggingface_access_token": "hf_xxx",
"huggingface_repository_id": "your-hf-username/your-model-repo"
}'
```
**Download the model archive**
This endpoint returns a redirect to a signed URL that streams the `.tar.gz` archive containing the model weights and configuration.
```bash theme={null}
curl -L -X GET "https://fine-tuning.api.nscale.com/api/v1/organizations/$ORGANIZATION_ID/jobs/$JOB_ID/download" \
-H "Authorization: Bearer $NSCALE_API_TOKEN" \
-o fine_tuned_model.tar.gz
```
#### With the Python client
The [`nscaledev/demo-nscale`](https://github.com/nscaledev/demo-nscale) repository ships a thin Python client around the fine-tuning APIs. The download helpers in [`nscale/finetuning.py`](https://github.com/nscaledev/demo-nscale/blob/main/nscale/finetuning.py) and [`nscale/files.py`](https://github.com/nscaledev/demo-nscale/blob/main/nscale/files.py) wrap the endpoints above so you can pull both the model archive and the original dataset files in one script.
```python theme={null}
from nscale import FineTuningClient
with FineTuningClient(api_token=token, organization_id=org_id) as client:
# 1) Download the fine-tuned model archive (.tar.gz)
client.jobs.download_model(
job_id="your-job-id",
output_path="exports/fine_tuned_model.tar.gz",
)
# 2) Download the dataset source files used to train the model
dataset = client.datasets.get("your-dataset-id")
client.files.download_file(
file_id=dataset["training_file_id"],
output_path="exports/train.csv",
)
if dataset.get("validation_file_id"):
client.files.download_file(
file_id=dataset["validation_file_id"],
output_path="exports/validation.csv",
)
```
Under the hood, `jobs.download_model()` calls the prepare-download endpoint to fetch a signed `download_url` and streams the response to disk. `files.download_file()` follows the same pattern for the original training and validation CSVs, so you keep a full record of the inputs alongside the trained weights.
## **Fine-tuning Job Cost Estimator**
The cost of a fine-tuning job is calculated based on the following factors:
* The number of token in your training and validation files.
* The number of traning and evaluation epochs.
* The base model you are using.