

What is Fine-tuning?
Fine tuning is the process of taking a pre-trained machine learning model and training it further on a specific dataset to adapt the model to a particular task or domain. In the context of this service, fine tuning allows you to customise foundation language models using your own data, improving performance on your unique workloads. A typical fine-tuning workflow consists of:- Selecting a base model: Choose a pre-trained model as the starting point.
- Providing training and validation datasets: Supply data that represents your target use case.
- Launching a fine-tuning job: Start the process, which will train the model on your data.
- Monitoring job status: Track progress, review logs, and handle errors.
- Retrieving the tuned model: Once complete, access your custom model for inference.
Prerequisites
- Service Token (JWT): A valid JWT is required to authenticate your requests. For instructions, please see our guide on how to create a service token.
- Organization ID: You can find your Organization ID by navigating to Settings → Organisation in the Nscale platform.
- A Fine-Tuning Dataset: The dataset from which to train your new model. Please follow the Dataset Creation Guide.
- Sufficient Credit: Enough account credit to cover the job’s cost. Each fine-tuning job has a $2.00 minimum spend, so make sure you have enough credit before starting. You can estimate the cost using the Fine-tuning job cost estimator. We include $5 free credit when you sign up to help you get started.
Create a Fine-tuning Job
To create a fine-tuning job, you need to select a foundational model as your pre-trained base model and configure the fine-tuning parameters. The following steps will guide you through the process of starting a fine-tuning job:Step 1 - Select a Base Model
The supported models we offer are detailed below.| Organization | Model Name | Model id for API | Context Length | Supported Batch Sizes | Training Precision |
|---|---|---|---|---|---|
| Meta | Meta-Llama-3-8B-Instruct | e5f6a7b8-c9d0-1234-efab-567890123456 | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
| Meta | Meta-Llama-3-8B | d4e5f6a7-b8c9-0123-defa-456789012345 | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
| Meta | Meta-Llama-3.1-8B | 28475dc6-e4be-49a4-8a87-660c4a7bb0ff | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
| Meta | Meta-Llama-3.1-8B-Instruct | 5b912da4-4a68-43eb-9224-38239535d934 | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
| Mistral AI | Mistral-7B-Instruct-v0.1” | f6a7b8c9-d0e1-2345-fabc-678901234567 | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
| Mistral AI | Mistral-7B-Instruct-v0.2 | a7b8c9d0-e1f2-3456-abcd-789012345678 | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
| Deepseek | DeepSeek-R1-Distill-Qwen-1.5B | b1432ae3-b4ce-4e12-be53-ab0555d00f93 | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
| Deepseek | DeepSeek-R1-Distill-Qwen-14B | c3d4e5f6-a7b8-9012-cdef-345678901234 | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
| Qwen | Qwen2-1.5B-Instruct | a1b2c3d4-e5f6-7890-abcd-ef1234567890 | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
| Qwen | Qwen2.5-14B-Instruct | b2c3d4e5-f6a7-8901-bcde-f23456789012 | 8192 | (4,8,12,16,20,24,28,32) | Float16 |
Step 2 - Create a Fine-tuning Job
Once you have selected your base model, you need to configure your fine-tuning job and create it. This involves specifying various parameters that control how the training process will behave. Below, we’ll explain each of these parameters. A fine-tuning job can be created using:Fine-tuning Job Configuration
When creating a fine-tuning job, you can configure various parameters to optimize the training process.Base Configuration
- name (string, required): The name of your fine-tuning job.
- base_model_id (string, required): The id of the foundation model to fine-tune. See the model id in the base model section for available options.
- dataset: Configuration for your training data. Details for creating a dataset can be found in the datasets
- id: (string, required): The id of the dataset to use for training.
- answer_column: (string, required): Column name containing expected outputs.
- prompt_column: (string, optional): Column name containing input prompts.
Hyperparameters
- n_epochs (integer, optional): Number of complete passes through the training dataset. Default: 1, Min:1, Max:20.
- n_evals (integer, optional): Number of evaluation runs on validation data. Default: 0, Min:0, Max:100.
- batch_size (integer, optional): Number of training examples processed in one iteration. See the base model section for supported batch sizes for each model. Default: 4
- learning_rate (float, optional): Controls how much to adjust the model in response to errors. Default: 0.00001, Min: 0.00000001, Max: 0.01
- warmup_ratio (float, optional): The percent of steps at the start of training to linearly increase the learning rate. Default 0.0, Min: 0.0, Max: 1.0
- weight_decay (float, optional): Weight Decay parameter for the optimizer. Default: 0.0, Min: 0.0.
- best_checkpoints (boolean, optional): Determines if the checkpoint of the epoch exhibiting the best validation metric should be saved. When set to false, the checkpoint after the last epoch is saved. Default: false.
- mask_prompt_labels (boolean, optional): Whether to exclude prompt tokens from the training loss (mask labels for the prompt). When set to true, only answer tokens contribute to the loss. Recommended for instruction-style datasets. Default: false.
- lora (object, optional): Configuration for LoRA fine-tuning.
Currently, we only support LoRA (Low-Rank Adaptation) fine-tuning. Full model fine-tuning will be supported soon.
- enabled (boolean, optional): Whether to use LoRA instead of full fine-tuning. Default: true.
- r (integer, optional): Rank of LoRA adaptations. Default: 8, Min:1, Max:64.
- alpha (integer, optional): Scaling factor for LoRA updates. Default: 8, Min:1, Max:64.
- dropout (float, optional): The dropout probability for Lora layers. Default: 0.0, Min: 0.0, Max: 1.0.
- trainable_modules ([strings], optional): A list of LoRA trainable modules, separated by a comma. Default: all-linear(using all trainable modules). Trainable modules for each model are:
- All models: k_proj, up_proj, o_proj, q_proj, down_proj, v_proj, gate_proj
Check the Status of your Jobs
You can check the status of your jobs using the list endpoint. These jobs can be filtered by job status:queued, running, completed or failed.
Monitor Training Metrics for your Job
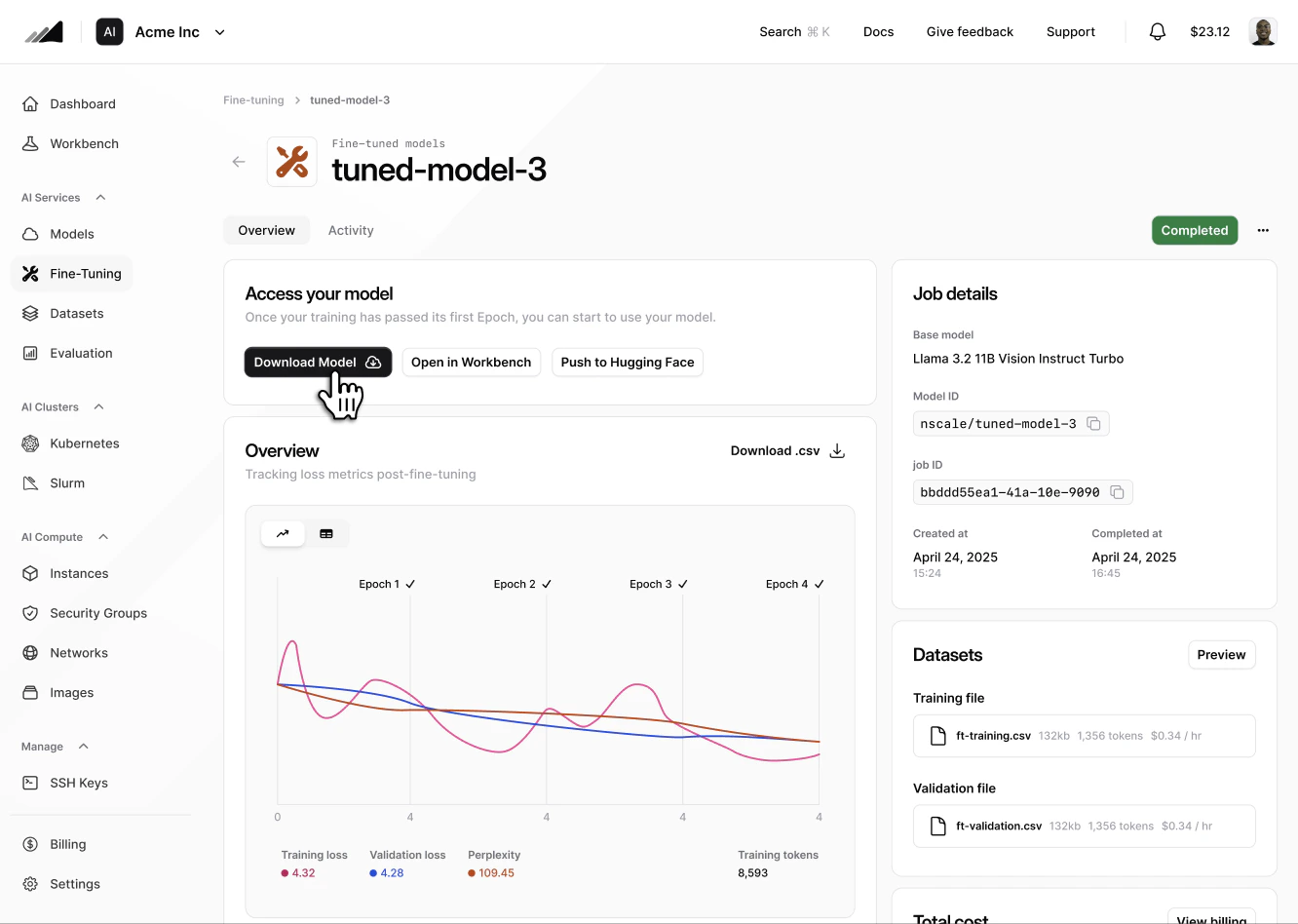
After launching a fine-tuning job, you can monitor its progress and evaluate its performance by retrieving training and evaluation metrics. The key metrics returned aretrain_loss, eval_loss, and perplexity.
These metrics help you understand how well your model is learning and when it might be finished or require intervention. Regularly polling this endpoint during training allows you to make data-driven decisions, such as stopping training early if the model converges or adjusting hyperparameters for future runs.
Export your Fine-tuned Model
Once your job has completed, you can export the model from the Console, via the API, or with the Python client shown in our demo repo. Each path produces the same artifacts — a.tar.gz archive of the model weights and configuration, or a copy pushed to your Hugging Face account.
From the Console
The Nscale Console provides a one-click path on the job details page.- Open console.nscale.com and go to AI Services → Fine-Tuning.
- Select the completed job you want to export. Export buttons are only enabled once the job status is
completed. - On the Access your model card, choose one of:
.tar.gz archive of the model weights and configuration to your browser. Downloads can be large, so allow your browser a moment to start showing progress — a confirmation banner appears on the card once the download has started.
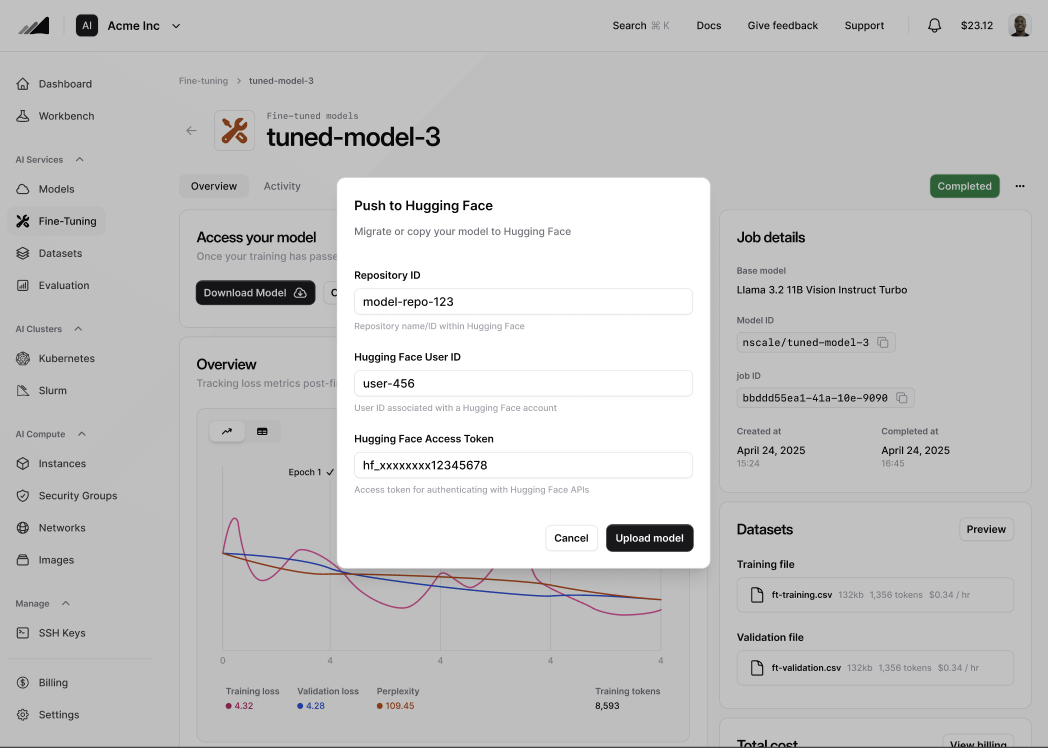
Via the API
Use these endpoints when you want to script exports without leaving your terminal. Push to Hugging Face The request body matches the fields collected by the Console dialog..tar.gz archive containing the model weights and configuration.
With the Python client
Thenscaledev/demo-nscale repository ships a thin Python client around the fine-tuning APIs. The download helpers in nscale/finetuning.py and nscale/files.py wrap the endpoints above so you can pull both the model archive and the original dataset files in one script.
jobs.download_model() calls the prepare-download endpoint to fetch a signed download_url and streams the response to disk. files.download_file() follows the same pattern for the original training and validation CSVs, so you keep a full record of the inputs alongside the trained weights.
Fine-tuning Job Cost Estimator
The cost of a fine-tuning job is calculated based on the following factors:- The number of token in your training and validation files.
- The number of traning and evaluation epochs.
- The base model you are using.
Each fine-tuning job has a $2.00 minimum spend, so make sure you have enough credit before starting.