Introduction
This cookbook walks you through creating a fine-tuning dataset from the PubMedQA corpus and running an end-to-end job on Nscale.- Dataset: PubMedQA
question and answer) that you can upload to Nscale and use to fine-tune a base model.
Requirements
- Python 3.9+
- Packages: datasets, pandas
- Nscale service token and organization ID
Generate the dataset CSVs
To use Nscale to fine-tune a model, you need a dataset in the required CSV format. The script below converts a small subset of PubMedQA dataset (~2k samples) to a simple Q/A CSV format. You can adapt the same approach for other datasets.- Input prompt: question
- Output target: long_answer when present, otherwise the categorical final_decision (e.g., yes/no/maybe)
convert.py, then run it:
pubmedqa_pqa_artificial_train_qa.csvpubmedqa_pqa_artificial_validation_qa.csv
question,answer.
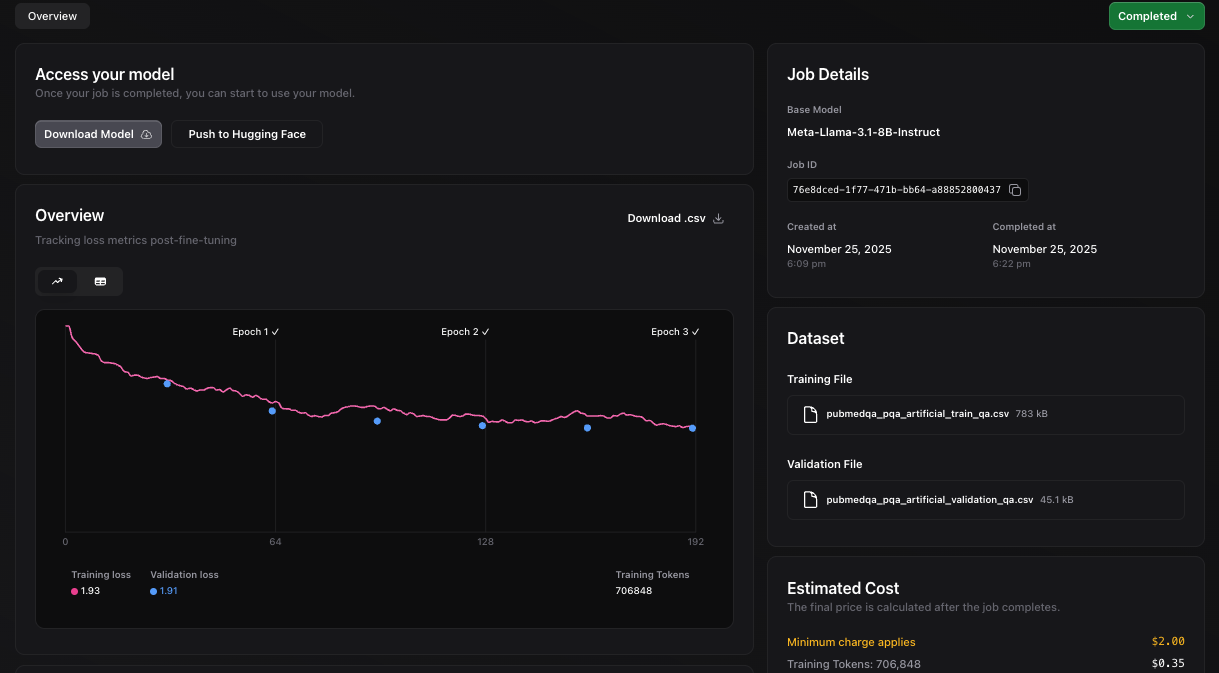
Create a fine-tuning job
You can create the fine-tuning job in the Nscale Console or via API. The steps below show how to do it with the Nscale Fine-tuning API.1. Upload files
Export your Nscale token and organization ID, then upload both CSVs. Save the returned file ids for the next step.2. Create the dataset
Use the two file ids returned above. Save returned dataset id to create a fine-tuning job:3. Create and monitor a fine-tuning job
Ensure you have enough credits in your account. First, list available base models and pick one. You can also find a list of available models in the Fine-tuning guide.question is the prompt and answer is the target output.
The example below uses meta-llama/Meta-Llama-3.1-8B-Instruct as the base model (ID: 5b912da4-4a68-43eb-9224-38239535d934). Replace base_model_id with the ID of your chosen model from the list above.